
61·
4 months agoPKD is special somehow. He’s the one author where, I think, the movies are better than the books pretty consistently. Maybe it’s luck or my flawed opinion.
PKD is special somehow. He’s the one author where, I think, the movies are better than the books pretty consistently. Maybe it’s luck or my flawed opinion.
I’ve not read them all but that sort of feels like how the culture novels are.

Thank you!
I think folks saying you don’t need math are right. But if you are having trouble with college algebra you might have trouble with CS. Or the teacher is bad.
Math really builds on itself at the stage where you are. Without good algebra calculus isn’t going to work well.
I’d try a different teacher. Online courses or repeating the course with another professor or something.
I’m late to this, but could a kind soul explain what I’m missing out on by using urxvt? I settled on it years ago and haven’t changed anything.
I’ve learned a lot by breaking things. By making mistakes and watching other people make mistakes. I’ve writing some blog posts that make me look real smart.
But mostly just bang code together until it works. Run tests and perf stuff until it looks good. It’s time. I have the time to write it up. And check back on what was really happening.
But I still mostly learn by suffering.
I just have to say “tastes like c” is a visceral way to say it. I approve.
I think blind itself drives some interesting bias. The public posts are pretty incel. You need a critical mass of folks at your company to have a company private board so it attracts folks from bigger companies. It doesn’t seem to represent average folks well. Unless I have no idea what average is.
I’m not sure what to do with that instinct. The overall results say a thing I wanted to hear. It all feels weird.
I’ve stopped using stash and mostly just commit to my working branch. I can squah that commit away if I want later. But we squash before merge so it doesn’t tend to be worth it.
It’s just less things to remember.
I’m just a hacker. I’ll never be a thought leader. But I am passionate about my work. And my kids.
I love solving the problems. I have a few posts on the company blog but they put a chat bot on it a while back and didn’t care that it felt offensive to me.
But I’m here, reading this. Maybe I’m grey matter.
My guess is the big video ram is high resolution textures, complex geometry, and a long draw distance. I honestly don’t know much about video games though.
The smaller install is totally the map streaming stuff. I’m unsure quite why it has to be so big, but again, I don’t know video games. I do recall you having to tell it where you want to start from and it’ll download some stuff there.
I recommend it. Try to go in blind.

Try your local library.
I feel lucky to have avoided this so far. It’s really not like this on my team. I write a fair bit of code and review a ton of code.
I think it was the EPA’s National Compute Center. I’m guessing based on location though.
When I was in highschool we toured the local EPA office. They had the most data I’ve ever seen accessible in person. Im going to guess how much.
It was a dome with a robot arm that spun around and grabbed tapes. It was 2000 so I’m guessing 100gb per tape. But my memory on the shape of the tapes isn’t good.
Looks like tapes were four inches tall. Let’s found up to six inches for housing and easier math. The dome was taller than me. Let’s go with 14 shelves.
Let’s guess a six foot shelf diameter. So, like 20 feet circumference. Tapes were maybe .8 inches a pop. With space between for robot fingers and stuff, let’s guess 240 tapes per shelf.
That comes out to about 300 terabytes. Oh. That isn’t that much these days. I mean, it’s a lot. But these days you could easily get that in spinning disks. No robot arm seek time. But with modern hardware it’d be 60 petabytes.
I’m not sure how you’d transfer it these days. A truck, presumably. But you’d probably want to transfer a copy rather than disassemble it. That sounds slow too.
Not looking at the man page, but I expect you can limit it if you want and the parser for the parameter knows about these names. If it were me it’d be one parser for byte size values and it’d work for chunk size and limit and sync interval and whatever else dd does.
Also probably limited by the size of the number tracking. I think dd reports the number of bytes copied at the end even in unlimited mode.
It’s cute. Maybe my favorite use of ai I’ve seen in a while.
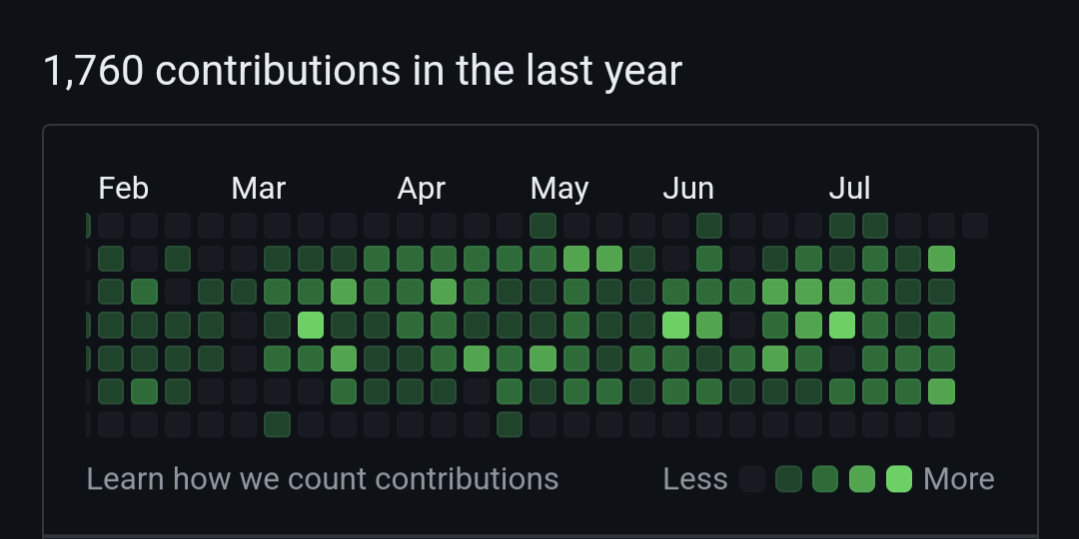
I wish it looked at contributions instead of just the profile page. Much more accurate roasting.

Mine looks a little like that. It’s my job though. Everything’s on GitHub.


A government stipend to make public art or open source software or literature or whatever sounds pretty great. It’s hard to see how we get there from here. But it’d be great.
France has something like it for artists I think.