- 11 Posts
- 21 Comments
{kind=link}

 7·11 days ago
7·11 days agoIf you can tariff penguin island you could also tariff polars, which isn’t slow.
{kind=link}
Code Didn’t Break — They Did
{kind=link}
Text encoding ‘standards’ were clearly the devil’s work, handed down to humanity to sow chaos and suffering.
{kind=link}
{kind=link}
{kind=link}
 107·2 months ago
107·2 months agoThis 80s metal band is making real music without synthesizers!
It did depend a little bit, what kind of machine/production line he was working on. Before he retired, he worked for an automation engineering company and had different projects in other EU countries, and tried to be understandable for people in those places. He once even coded some Siemens control panel for an aluminum oven loading robot in the czech republic and tried to translate everything to czech with a dictionary (to have the panel info available in czech,english and German). He did of course speak to the foreman of the workers to get it correct.
My dad used that a lot to program Siemens Step5 and Step7 PLCs. I think it was German but names were 8 chars since this was straight from the 80s. When he fixed old machines or updated them with new PLCs he had to do full rewrites a few times because nothing was documented in old school machinery.
{kind=link}
 6·2 months ago
6·2 months agoThat is something that some tech savy Lemmy users could already easily do. I repost stuff from all over the web. But some systematic preservation of good old subreddits aught to be automated.
Important context and a good decision
4chan at least had a consistent brand of being the anti-social network and being full of Nazis, weirdos, pedophiles and people who are just anti-social for the lulz. You couldn’t ruin 4chan.
Twitter’s image was being the “internet town-square for serious thinkers” with politicians, scientists, journalists and a small but good measure of standard shitposters. Loosing that brand diminishes it’s value massively. Unfortunately neither Bluesky nor Mastodon was able to catch that clientele yet.
It’s the famous “As long as your not Google, Amazon or Apple” licence.
For a user without much technical experience using a ready-made gui like Jan.ai with automatic model download and ability to run models with the ggml library on consumer grade hardware like mac M-series chips or cheap GPUs by either Nvidia or AMD is probably a good start.
For a little bit more technically proficient users Ollama is probably a great choice to start to host your own OpenAI-like API for local models. I mostly run gemma2 or small llama 3.1 like models with that.
The market will segment away from the current tech anyway. CATL Sodium-ion with comparatively low densities but also extremely low prices per kWh will likely win the low-end market and the market for stationary solutions. This is just due to the much lower resource costs. The high-end will be up for things like this battery by Samsung (or other comparable pilot products). The current technology will likely be in a weird middle spot.
Depends on what you do with it. Synthetic data seems to be really powerful if it’s human controlled and well built. Stuff like tiny stories (simple llm-generated stories that only use the complexity of a 3-year olds vocabulary) can be used to make tiny language models produce sensible English output. My favourite newer example is the base data for AlphaProof (llm-generated translations of proofs in Math-Papers to the proof-validation system LEAN) to teach an LLM the basic structure of Mathematics proofs. The validation in LEAN itself can be used to only keep high-quality (i.e. correct) proofs. Since AlphaProof is basically a reinforcement learning routine that uses an llm to generate good ideas for proof steps to reduce the size of the space of proof steps, applying it yields new correct proofs that can be used to further improve its internal training data.
 624·9 months ago
624·9 months agoNo idea how Fortnite works. But can you (realistically) use the Cybertruck to cut off your enemies fingers with it’s automatic doors.
Na SpaceX would just use his neuralink chip it to automate the team that keeps Musk distracted from messing with important things in the company with a simple AI
{kind=link}
Im sorry, but as a language model, I don’t have the capability to perceive or assess physical appearances. I am however sure you have other desirable qualities.
{kind=link}
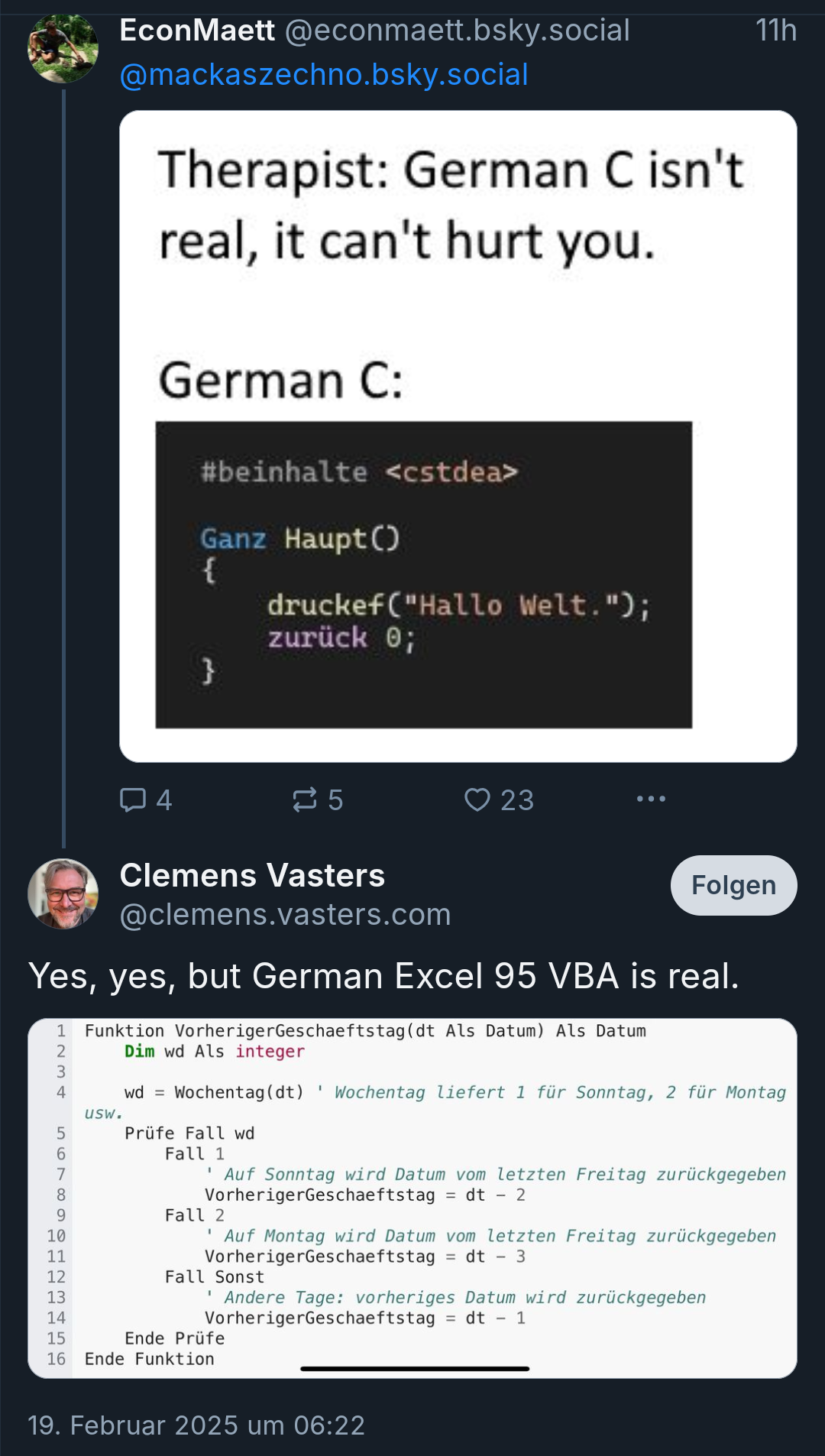
Na this is about R
Also multiple systems included. the old base plotting from the 90s, lattice for really custom things, ggplot as the most humanely understandable and reasonable system for composing plots and great interfaces to plotly and d3.js
RCpp is crazy good. You can super easily write Cpp inline with R code, it is easy to use and half of the tidyverse is written in it.
{kind=link}
{kind=link}
This is a bluesky screenshot, not a twitter screenshot. This is to show, where I reposted this from.